
Still unemployed. Still shipping.
Since the last update, the campaign has kept moving. The numbers did not reward it.
That is the real update.
The project is still clarifying the same structural lesson. Not every idea wants the same asset package. But this cycle added a harder lesson on top of that. A good idea can still get weak distribution. Good work can still disappear. And when the person running the system is depressed, depleted, and staring down a bad job market, a weak signal does not stay politely inside the metrics. It leaks into motivation, sequencing, and belief.
What happened since the last update
The work did ship. Two RAG pieces went out (Practical Retrieval Authorization Patterns for RAG Systems, RAG Is Data Access: Retrieval Authorization Is the Control), as well as a post about Secrets and Tokens – Rotation SLAs, Blast Radius, and Attacker Dwell Time. Week Six itself is here because accountability demands it.
But the shape of the campaign is getting more complicated.
Agents Are Identities still looks like a fuller arc. Blog, support layer, and YouTube all made sense on paper.
RAG looked like it was earning the same kind of treatment. In practice, it got the practical post, the anchor post, and the social support, but the chain started breaking before the next asset could justify its cost. The planned video in that chain is RAG retrieval authorization in plain English. It belongs to the next cycle if the signal can justify it. That matters.
Week Four was also split into two parts, with an idea from that post becoming a separate, vendor-neutral piece I added to the content calendar. That was a clear reminder that one idea does not always stay inside one asset.
Mini-campaigns, defaults, and where they break
What this project actually turned into is not one campaign with a fixed asset count. It turned into a set of mini-campaigns.
Each idea leaves the gate with a default support pattern. One canonical asset. One support or distribution asset. One back-catalog connection. The metadata and prep work that make the thing real. Sometimes measurement. Sometimes a human explainer asset. From there, the idea either earns more surface area or it does not.
That is still a useful model. The workflow is clarifying template defaults instead of forcing me to rebuild every motion from scratch.
Technical posts tend to want a familiar spine. Canonical post. Slug. Tags. Featured image. Related reading. Supporting links. A LinkedIn wrapper. Sometimes a video if the thing needs a human explainer.
Video has its own default package, too. A source asset. Talk track. Deck or screen plan. Description links. Matching anchor. At least one back-catalog bridge. It is different work.
Meta PMM posts are different again. They need the status update, the workflow lesson, and the correction for next time.
The point of defaults is not rigidity. The point is speed and clarity. But this cycle also clarified something else. Defaults are not quotas. They are starting assumptions. The topic, the channel, the signal, and the human running the system still get veto power.
The trend line
The numbers are not good, but they are useful.
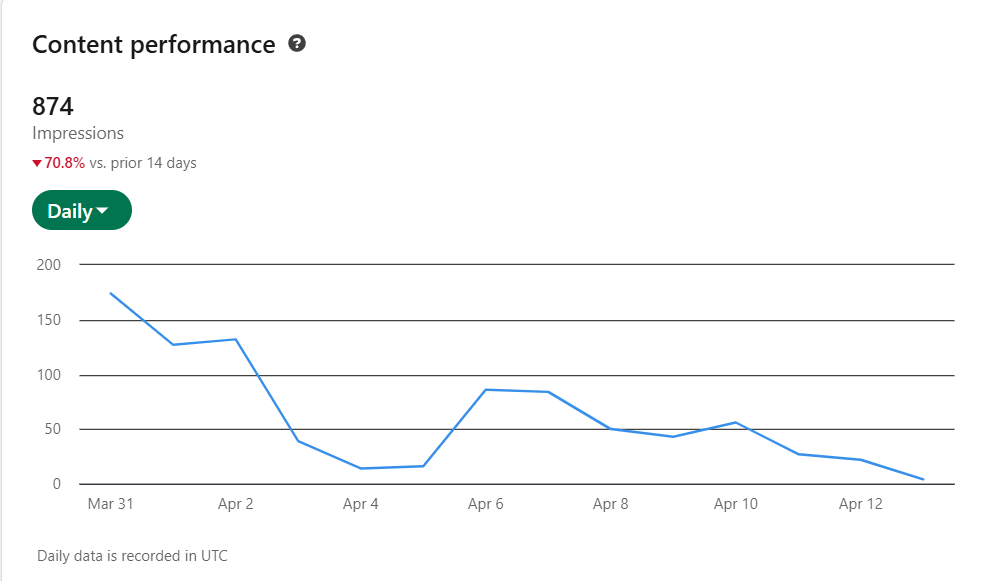
Week Two was still the strongest early checkpoint. At that point, the blog had 36 views and 28 unique visitors, LinkedIn had produced 965 impressions in a single week, and the strongest trust signal on the board was 4 sends.
By Week Four, that had already dropped to 12 WordPress views, 10 visitors, 558 LinkedIn impressions, 299 reached, 8 engagements, and 0 sends. That was the first clear warning that the carry was getting weaker.
This cycle is worse in a different way. LinkedIn’s surface area partially recovered to 874 impressions and 376 members reached, but discovery was still down 70.8 percent versus the prior 14 days. More importantly, the transfer into the blog collapsed. In the current WordPress snapshot, both new RAG posts are sitting at 1 total view each.
Week Two showed an early lift. Week Four showed the drop. Week Six shows that a small recovery in surface area does not mean the system is working. The handoff from social visibility to actual blog readership is breaking.
The good, the bad, and the ugly
The good news is that the project still produces a signal. Things are shipping. The defaults are clearer. The campaign structure is real enough now that I can see patterns instead of just tasks.
The bad news is that the signal is weak. RAG did not travel (and it should have, it’s something Agentic AI relies on that no one is talking about). The social layer did not do enough to carry the supporting content. And a larger asset package on paper does not mean the next asset is actually earned in practice.
The ugly is that weak numbers hit differently when the rest of life is unstable.
The human factor
This is the part Asana cannot show cleanly.
It can show slips. It can show incomplete tasks. It can show dated work, moving or not moving. What it cannot show very well is what it feels like when the same person assigned to the asana tasks is also dealing with a desert of job prospects, endless applications, even more rejections, or just ghosting you, hoping you get the hint. With ever-shrinking unemployment benefits and the pressure of supporting a wife and toddler, the future looks increasingly bleak.
That changes the work.
It changes whether the next video feels like a smart extension or a bad bet. It changes whether a weak metric feels like feedback or like judgment. It changes whether the Asana board looks like a solid plan or like a list of things I am too depleted to finish.
That is not abstract in this cycle. It showed up directly.
The YouTube work I really wanted to produce did not just slip because of sequencing. It slipped because I am depressed, short on motivation, and running low on belief that more effort will create a different outcome. The project is teaching me something uncomfortable here. Human capacity is not a footnote in the content system. It is the core part of the system.
And this is where the numbers get dangerous.
Weak performance makes it very easy to ask the wrong question. If the views are low enough, if the impressions keep shrinking, if the job market keeps ignoring the work, does that mean the work itself is bad? Does it mean I was wrong about what I thought was good? Does it mean the whole effort is a waste?
I am not sure the data proves that.
What the data proves is that good work, weak distribution, cold market conditions, and a depressed operator can all exist at the same time. The system is not paying effort back cleanly or fairly right now. That is different from the work being worthless. It is different from me being worthless. But it would be dishonest not to say that this cycle made that distinction harder to hold.
What changes next
The next correction is not to force more output.
It is to get more honest about what the next asset in a chain has to earn.
If the support layer does not do its job, the next asset is not automatically justified just because it was on the original plan. If the human running the system is running on fumes, that is not noise in the model. That is the model input.
So the adjustment is straightforward, even if it is not fun.
The goal is not to flood every channel.
The goal is to give each idea the minimum viable asset set it needs to move, build an audience, and prove whether it deserves more support than the default.
This cycle did not prove momentum. It proved friction. It proved slippage. It proved a weak transfer. It proved that the human factor is not optional in context.
That is bad news bears, but it is also useful information.
Until next time,
Thanks for Listening.

Leave a comment