
I missed the Week 8 update.
Then I missed Week 10.
Now that Week 12 has come around, pretending this was still a normal biweekly cadence would have been a false narrative.
So this is Week X.
The missing six weeks.
That sounds worse than it is in one way, and exactly as bad as it is in another.
The content engine did not stop. I kept publishing. I kept researching. I kept building. I kept using the work as public proof for the kind of technical product marketing I want to keep doing.
But the public operating record fell behind.
That matters because this series was never just about what posts went live. The point of the meta-PMM series was to show the work behind the work. What shipped. What slipped. What the numbers said. What the system revealed. What broke when the process met actual pressure.
This time, the process met actual pressure.
The work behind the work stopped.
The easiest version of this post would be, “I got busy.”
The more accurate version is that the content kept shipping, but the PMM work around the content slowed down. The measurement. The positioning. The calendar hygiene. The recirculation. The public accountability layer. The part where I stop being only the writer and act like the product marketer for my own body of work.
That is the work this series is supposed to track.
And that work did stop for a while.
Since Week Six, I have continued building out more posts that still fit the larger TechThatMattRs arc. They were the same operator-first thread I have been building around identity, agents, access, workflow, evidence, and the gap between clean diagrams and actual systems.
The Workflow Got Faster. The Record Got Fuzzier came first. That one has become the hinge for a lot of this work. The idea was simple: better workflows are good, but the record still has to tell the truth. Once AI systems start helping with real work, the question is not only whether the work got done. It is also who asked, what acted, what changed, and what evidence survived.
Then came the Agent incident playbook: first 60 minutes. That one moved the agent governance conversation into incident response. Not “AI threat landscape” mumbo jumbo. More like: if an agent-linked incident happens, what do you preserve, what do you stop, what do you scope, and how do you avoid turning a weird authority problem into a fog machine?
AI Identity Management at the Scale of One was the dogfood post. I have been talking about agents as identities, so I started treating my own AI-assisted workflow as a separate identity. Clear ownership. Scoped access. Named operators. Not perfect. Not enterprise architecture. But real enough to expose the same fuzzy edges I keep writing about.
Quantum’s First Real Job widened the aperture. It was still operator-shaped, but it moved outside the identity/security lane into quantum, software layers, and the practical question of when early infrastructure becomes something normal teams have to reason about.
Mandiant Got Inside. The AI Threats Were Not What Anyone Expected was the timely one. It had a shelf life. It jumped the line because the report gave me a clean way to make a point I keep coming back to: the first operational failures around AI are not always cinematic. They are often familiar security problems wearing a newer jacket. Bad assumptions. Weak controls. Poor visibility. Delegated authority without enough evidence.
And then Joiner-Mover-Leaver for AI Agents shipped in the recovery window. That one mattered because it took a familiar identity governance motion and applied it to agents directly: create, rotate, retire. Not because agent governance needs a completely new religion, but because some old controls still work when you stop pretending the actor must be human.
So no, that work did not stop.
But the public record did.
That is the uncomfortable part.
The meta-PMM series exists to report the operating reality. If that record falls behind, the system gets fuzzier even when work is shipping.
That is almost too on the nose, given the post I published right after Week Six. It is one thing to write about fuzzy records. It is another thing to notice your own system of record getting soft around the edges.
Week 8 slipped.
Week 10 slipped.
Week 12 became less a scheduled post and more a flashing light on the dashboard.
Some recirculation work slipped, too. Not because the topics were bad. In some cases, the side stories were too big for the wrapper. The older meta-PMM posts had a rhythm where the accountability update carried a B-story: a broader lesson about distribution, content operations, or technical product marketing craft. That worked when the update was current.
It stopped working once the update itself was late.
At that point, trying to cram six weeks of missed accountability, performance data, shipped posts, operational lessons, and PMM side essays into one neat post would have turned the update into a junk drawer with headings, which I am trying to avoid. That said…
What the numbers say
The numbers are still small. That is fine. This is a young site with a very specific audience and a very specific job.
From April 13 to May 15, WordPress showed 157 views, up 33%, and 125 visitors, up 49%. No likes. No comments. The homepage and latest posts view accounted for 123 views.
That homepage number needs some context.
During the gap, I moved the site from the old WordPress.com subdomain to a real domain: techthatmattrs.net. That matters because the homepage became the new front door. Some of that traffic is normal, latest-post navigation. And some of it is bots, now that I have a real front door.
That is infrastructure showing up as analytics.
The individual post numbers were small, but still useful. Week Four, Agent Inventory and the Agent Register, and The Workflow Got Faster. The Record Got Fuzzier; each showed 5 views in the earlier window. RAG is Data Access, and Approved Tool, Expanding Agent, each showed a smaller but relevant signal. The older Windows time-sync post still pulled a few views, too, which tracks with something I have seen before: practical troubleshooting content has a long tail because boring problems keep ambushing people, and it’s exactly why I wrote it, for the next guy who had to solve the same dumb problem.
The May 14 to May 20 refresh showed 20 views, up 122%, and 14 visitors, up 75%. The homepage/latest posts had 10 views. Mandiant Got Inside had 4 views. Week Four and RAG Is Data Access each had 1 view.
Again, these are not giant numbers. They are an early-stage signal.
The site is becoming a real library, but LinkedIn is still the discovery layer.
LinkedIn made that pretty obvious.
In an earlier snapshot, I had 706 post impressions, up 553.8% over the prior 7 days, 1,558 followers, 249 profile viewers over 90 days, and 33 search appearances.
By the May 14 to May 20 refresh, LinkedIn had jumped hard: 2,325 post impressions, up 1,080.3% over the prior 7 days. Content performance showed 2,324 impressions, up 1,079.7%. Discovery showed 1,562 members reached, up 1,149.6%. Engagements were 12, up 140%. Social engagement was 11 reactions, 0 comments, 0 reposts, 1 save, and 0 sends.
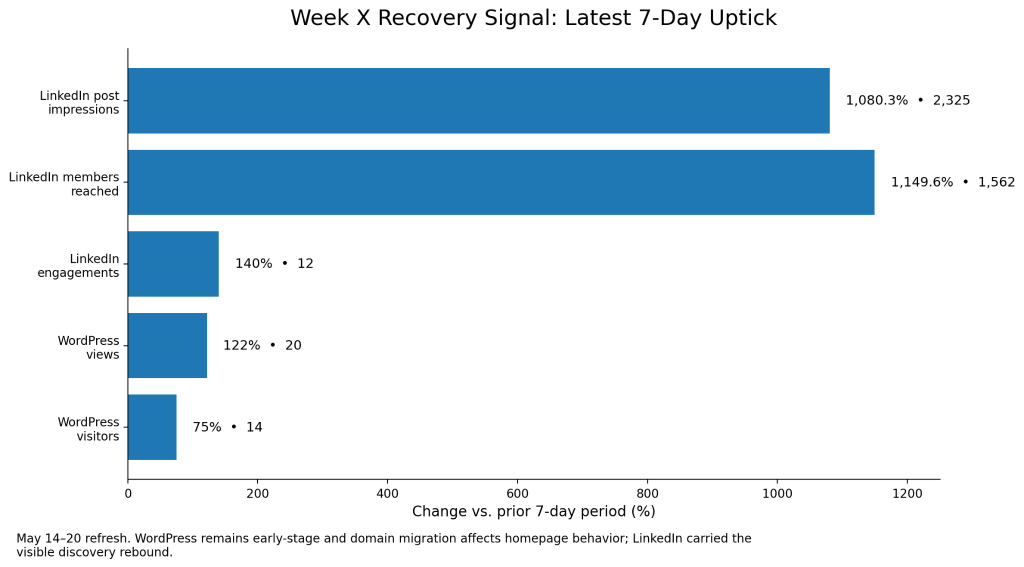
The top LinkedIn post in the latest window was not one of my owned blog posts. It was a reshare of a @SaltyCloud post that hit 1,688 impressions. The Mandiant post followed with 191 impressions. And my repost of an older Unite.ai post I did about agentic AI and non-human identities landed at 143 impressions.
The bottom line for this period really comes down to this: relevant, topical posts tied to more established names have a much bigger immediate reach curve than a new blog link from a small site.
That does not make the blog less important. It just means I do not have the audience yet. When I can connect my point of view to conversations that already have an audience, it boosts the signal, and readers engage.
That is useful to know. It is also a little tricky to operationalize without becoming an @examplehumanandorcompany tag menace to society.
What was going on backstage?
Some of the work was below the waterline. Not all the work becomes a post right away.
Some of it looks like infrastructure.
During the gap, I moved the site URL from the default WordPress.com subdomain, https://iwashuman2021-goebr.wordpress.com, to the real domain, https://techthatmattrs.net. I kept working through the question of defined agent identities. I started treating ChatGPT and Claude less like vague helpers and more like named operators in the workflow. That sounds small until you care about attribution. Then it becomes the whole problem.
I also kept working through connector and MCP patterns across Gmail, Yahoo, GitHub, Asana, and Google Docs. That work is not glamorous. It is mostly access, authentication, scope, handoffs, and figuring out where the tool boundary actually lives.
Which is why I keep writing about the kinds of things I keep writing about, I’m dogfooding it myself, and trying to see what it looks like up close.
I also reopened the Incredibuild lab image work. That project started as a scrappy all-in-one deployment Docker image from years ago, built while I was trying to understand a complex product well enough to interview for a role. It still gets pulled, daily, for some reason. It still has value. And it still needs a lot of cleanup because old working artifacts have a way of becoming accidental infrastructure, and I don’t want to be the guy who doesn’t update his code.
Then there was the Asana cleanup.
Asana is supposed to be the source of truth for this content engine. Not a suggestion box. Not a guilt museum. Not a second, less reliable memory.
So I cleaned it up.
Parent tasks and subtasks got aligned to publish dates. The content calendar was revised around a more regular pacing pattern. Mondays became the PMM slot. Tuesdays and Thursdays became technical blog days. Friday became the wildcard, recirculation, topical, or thought-leadership lane.
The production workflow got standardized across the major content tasks:
Research. Write Draft. SEO / SLUG / Excerpt / Tags. Perchance Image Generated. Layout. LinkedIn. Publish.
That does not make the work easy. It makes the work easier to see, sequence, and finish.
The job search was not separate from the content engine
The other big reason the Week X draft slipped is simpler: I had interviews.
Several of them.
And interview prep is not separate from this project. It is one of the reasons this project exists.
The job-search spreadsheet is long. For a while, it was also too quiet. With roughly five weeks left on unemployment, that silence was not exactly calming. Then the pipeline started moving. Recruiter screens. Hiring manager interviews. Follow-up conversations. A take-home assignment. Prep docs. A live GTM deck.
I am not going to name every active process here because some of that is still in motion. But the work was real: company breakdowns, role-fit reads, positioning notes, interview answers, compensation reality checks, product research, and a take-home GTM launch plan for a cyber GRC product.
That last one is not a small lift.
It asks for a 90-day go-to-market strategy, a 30/60/90 roadmap, success metrics, pipeline thinking, AE net-new motion, AM cross-sell motion, field enablement, demand strategy, and speaker notes. In other words, it is exactly the kind of work this content engine is supposed to prove I can do.
That is the honest tradeoff.
The blog created proof. The proof helped support interviews. The interviews consumed the writing window.
That is the system doing the thing it was built to do, then forcing a scheduling decision.
That is the part I do not want to smooth over. The content engine was built to create proof of work. When that proof started turning into interviews, the content calendar absorbed the hit. That is a good outcome with a real cost.
What broke
The system did not break in one dramatic way.
It bent in several practical ones.
First, the meta-PMM update tried to carry too much. It was supposed to be an accountability post, performance recap, operating note, and a B-Story PMM essay all at once. That worked when the cadence was current. It did not work once the gap got bigger.
Second, the calendar had too many active promises and not enough slack. That is a boring project management sentence, which is why it is probably true, and one I am still struggling with, as I keep forgetting it’s just me.
Third, interview work was real work, but it did not have a clean capacity lane inside the content calendar. It sat outside the publishing model while still pulling from the same time, energy, and brainspace, if not more.
Fourth, the system of record had drifted. Some things were accurate. Some things were old. Some things were parked but still looked active. Some things had subtasks that did not match the newer production model.
That is how this content system became unstable.
Not because anything is obviously on fire.
But because the human element is still an army of one.
What changed
The fix was not motivational.
It was operational.
Asana is back to being the source of truth. If a task moves, Asana moves. If something is parked, Asana says parked. If something is killed, it gets killed instead of being carried around like a cursed heirloom. If a task has a publish date, the parent, subtasks, and calendar should all agree.
The content calendar now shows publish targets, not every support task. That matters because a calendar packed with every tiny step stops being a calendar. It becomes noise with dates attached.
The channels are clearer now.
Monday is PMM/accountability.
Tuesday and Thursday are technical blogs.
Friday is wildcard, recirculation, topical commentary, or thought-leadership work.
Leveraging AI agents as their own entities has enabled more effective workflows and helped break parts of the backlog. When I can automate workflow updates directly against the tasks, the record gets cleaner, more accurate, and more timely.
What comes next
This post catches the record up.
That is its job.
Good ideas are still scope creep if they enter the active lane at the wrong time.
The point of this project was never to prove that I could keep the system clean forever.
The point was to build a real content engine in public and learn what happens when it meets real pressure.
It met real pressure.
It got messy.
It kept producing.
Now the record catches up.
Related reading
This post connects most directly to The Workflow Got Faster, The Record Got Fuzzier because that is the operating principle I ended up having to apply to my own content process.
It also connects to AI Identity Management at the Scale of One, because some of the below-the-waterline work was about turning agent identity from a principle into a working habit.
And it points back to TechThatMattRs: Week Six – The minimum viable asset set, which was the last clean checkpoint before the record started drifting.

Leave a comment